



Editor’s Note: The podcast is recorded using NotebookLM technology. The data fed into the “notebook” is listed below the article. One of the AI podcasters struggled at times to pronounce “DeepSeek.”
The DeepSeek Revolution: How a Chinese Startup is Rewriting the Rules
Silicon Valley wasn’t ready for this: an obscure Chinese AI startup, DeepSeek, has emerged seemingly out of nowhere to challenge tech’s biggest players—delivering cutting-edge models at a fraction of the cost. Their groundbreaking approach to artificial intelligence development has not only matched the performance of industry leaders but has done so at a fraction of the cost, prompting a fundamental reassessment of how AI advancement should be pursued.
The Quiet Revolution
DeepSeek's story begins in the bustling city of Hangzhou, China, where founder Liang Wenfeng, a former quantitative finance expert, saw an opportunity to approach AI development differently. Rather than following the conventional wisdom of massive computing power and billion-dollar budgets, DeepSeek chose a path of efficiency and innovation.
The company's journey started within the walls of High-Flyer, a successful AI-powered hedge fund. This unique incubation environment provided not just funding but also a practical testing ground for DeepSeek's early innovations. Away from the spotlight and intense scrutiny of Silicon Valley, the team had the freedom to experiment with unconventional approaches that would later prove revolutionary.
A Perfect Storm of Innovation
DeepSeek's success can be attributed to three key strategic decisions that set it apart from its competitors:
1. The Efficiency Revolution
At the heart of DeepSeek's breakthrough is its innovative Mixture-of-Experts (MoE) architecture. Unlike traditional AI models that activate all parameters for every task, DeepSeek's approach is remarkably selective. Their flagship model, DeepSeek-V3, contains 671 billion parameters but activates only 37 billion for any given task – about 5.5% of its total capacity. This selective activation not only reduces computational demands but also enhances the model's efficiency and scalability.

Another way to look at Mixture of Experts is with a visual metaphor.

2. Balancing Openness with Innovation
Following in the footsteps of successful open-source AI initiatives like Meta's LLaMA and Mistral AI, DeepSeek has embraced transparency while adding their own innovations. Their approach combines open-source accessibility with unique architectural improvements, particularly in their implementation of the Mixture-of-Experts system. This strategy allows them to benefit from community contributions while maintaining distinctive technological advantages in how their model processes information.
3. Strategic Resource Management
Perhaps DeepSeek's most prescient move was their early acquisition of advanced AI chips, particularly Nvidia's A100 processors, before U.S. export restrictions were implemented. This foresight provided them with the essential hardware needed for development while their competitors struggled with supply chain constraints.
Breaking the Cost Barrier
One of the most striking aspects of DeepSeek's success is its cost-effectiveness. The development of DeepSeek-V3 reportedly required less than $6 million – a stark contrast to the billions spent by their competitors. This efficiency isn't just about frugality; it represents a fundamental rethinking of how AI models can be developed and trained.
The Reasoning Revolution
DeepSeek's two-pronged approach to AI development has yielded remarkable results. Their foundation model, DeepSeek-V3, released in late December 2024, showcases their innovative architecture with its 671 billion parameters. But it's their latest release, DeepSeek-R1, unveiled in January 2025, that has truly captured the industry's attention. R1 represents a fundamental advancement in AI reasoning capabilities, demonstrating an ability to match or exceed OpenAI's o1 model across key benchmarks, particularly in mathematics and coding tasks. The model's success on Apple's App Store, where it reached the top position in multiple countries including the United States, provides real-world validation of its capabilities.
Global Implications
DeepSeek's emergence has broader implications for the global AI landscape. It challenges the assumption that breakthrough AI development requires massive resources and demonstrates that innovation can flourish under constraints. The company's success has already impacted financial markets, with shares of major U.S. AI-related companies experiencing significant volatility in response to DeepSeek's rise.
Looking Ahead
As DeepSeek continues to evolve, several questions emerge about the future of AI development:
Will their efficient approach become the new standard for AI model development?
How will established players respond to this challenge to their dominance?
What role will open-source development play in the future of AI?
One thing is certain: DeepSeek's rise marks a pivotal moment in the history of artificial intelligence. Their success demonstrates that the next breakthrough in AI might not come from massive computing power or billion-dollar budgets, but from innovative thinking and efficient resource use.
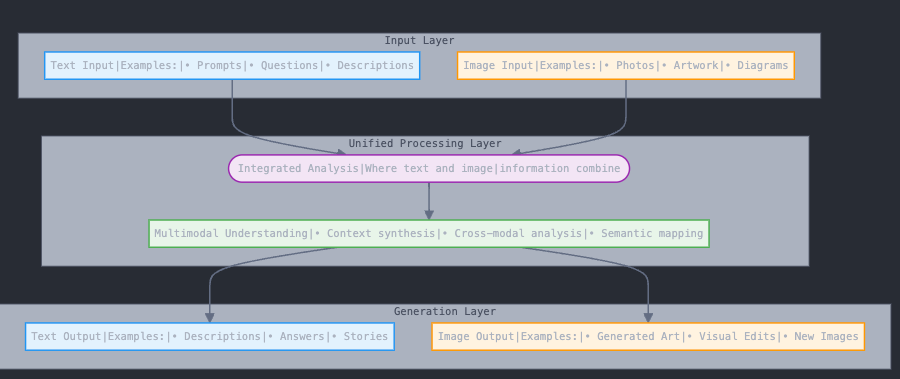
The DeepSeek story reminds us that in technology, as in nature, adaptation and efficiency often triumph over raw power. DeepSeek's latest innovation, the Janus-Pro-7B, represents a fundamental shift in how we think about AI capabilities. Released on January 27, 2025, this model introduces what DeepSeek calls a "unified multimodal understanding and generation" approach. Think of it as a bridge between different forms of communication - text and images - allowing the AI to not only understand both but seamlessly translate between them.
What makes Janus-Pro particularly noteworthy is its architectural efficiency. While many multimodal models require separate systems for understanding and generating content, Janus-Pro integrates these capabilities into a single, unified framework. This integration isn't just about technical elegance - it allows the model to achieve superior performance while maintaining a relatively modest parameter count of 7 billion, a fraction of what many competing models use.
The model's performance claims are significant: it reportedly outperforms both OpenAI's DALL-E 3 and Stability AI's Stable Diffusion XL across multiple benchmarks. These aren't just incremental improvements - they represent a leap forward in the field of AI-powered visual understanding and creation. Released under an MIT license, the model's open-source nature means that researchers and developers worldwide can examine, improve, and build upon this technology.
The rapid succession of these releases - from DeepSeek-V3 in December 2024 to R1 in mid-January 2025, and now Janus Pro - paints a picture of a company that isn't just challenging the established order but actively redefining the pace of AI innovation. Each model brings its own specialization: V3 with its efficient architecture, R1 with its advanced reasoning capabilities, and Janus Pro with its multimodal abilities.
As the AI industry grapples with this new paradigm, one thing becomes clear: the future of artificial intelligence may not be determined by who has the most resources, but by who can innovate most effectively with what they have. DeepSeek's story is still unfolding, but it has already changed our understanding of what's possible in AI development.

Vocabulary Key: DeepSeek's Models Explained
DeepSeek-V3 (Foundation Model):
The backbone of DeepSeek’s ecosystem, leveraging Mixture-of-Experts (MoE) architecture to activate only the most relevant parameters (5.5% of 671B total) for specific tasks. This reduces costs and hardware requirements without sacrificing performance.DeepSeek-R1 (Reasoning Specialist):
Designed for advanced reasoning, coding, and math tasks, R1 delivers world-class performance at just $6 million in development costs, a fraction of what competitors spend.Janus Pro 7B (Multimodal Innovation):
A revolutionary AI model capable of analyzing and generating both text and images with a unified multimodal architecture. Operating in the 1B–7B parameter range, it achieves superior performance while remaining highly efficient.Mixture-of-Experts (MoE):
A specialized AI architecture that activates only the most relevant parts ("experts") of a model’s parameters for each task. This selective activation drastically reduces computational load and cost, making models both efficient and scalable.Unified Multimodal Architecture:
An AI system that processes and generates multiple types of data—like text and images—within a single, integrated framework. Unlike traditional models that rely on separate systems, this unified approach simplifies the architecture and improves efficiency.Parameter Range:
The total number of adjustable components (parameters) in an AI model, which determine its capacity to "learn" patterns and tasks. A smaller parameter range (e.g., Janus Pro’s 1B–7B) often indicates greater efficiency, while maintaining strong performance in specialized tasks.
Breaking News: DeepSeek Launches Janus Pro 7B - A New Milestone in Multimodal AI
In yet another surprise announcement that has sent ripples through the AI community, DeepSeek unveiled its latest innovation today - the Janus Pro 7B model. This release, coming just days after their groundbreaking R1 model, marks DeepSeek's bold entry into multimodal AI technology.
A Unified Approach to AI
Janus Pro 7B represents a significant departure from traditional multimodal AI architectures. While most existing systems use separate models for understanding and generating different types of content, Janus Pro introduces what DeepSeek calls a "unified multimodal understanding and generation" framework. This approach allows the model to seamlessly process and generate both text and images within a single, efficient system.
Technical Innovation
What makes Janus Pro 7B particularly remarkable is its efficiency. With just 7 billion parameters - a relatively modest number in today's AI landscape - the model reportedly outperforms industry standards like OpenAI's DALL-E 3 and Stability AI's Stable Diffusion XL on multiple benchmarks. The model employs the SigLIP-L vision encoder for processing 384 x 384 image inputs and features a specialized tokenizer with a downsample rate of 16 for image generation.
Open Source and Accessible
Following DeepSeek's commitment to open development, Janus Pro 7B is released under an MIT license and is available on Hugging Face. This accessibility allows researchers and developers worldwide to examine, modify, and build upon the technology, potentially accelerating innovation in the field.
Market Impact
The announcement has already made waves in the tech industry, contributing to significant market movements, including a reported 17% drop in Nvidia's stock price. This reaction underscores the market's recognition of DeepSeek's potential to disrupt the established AI landscape.
Looking Ahead
With the release of Janus Pro 7B, DeepSeek continues its rapid pace of innovation, demonstrating that breakthrough AI developments can come from unexpected places. The model's efficient architecture and strong performance suggest that we may be entering a new era of AI development, where cleverness and optimization trump raw computing power.

This latest release, completing a trifecta of major announcements from DeepSeek in just over a month, signals that the AI race is far from over - in fact, it might just be getting started.
Editor’s Note: In a sign of how quickly things are changing, I am posting a correction, as per Hugging Face. "The use of the Janus Pro 7B is subject to the DeepSeek License." [not the MIT Open Source license.] For the latest on the Janus Pro 7B model, follow the page on Hugging Face here.
FAQs: Understanding DeepSeek and Its AI Breakthroughs
What makes DeepSeek’s AI models different from traditional models?
DeepSeek models use Mixture-of-Experts (MoE) architecture, which activates only the most relevant parameters for each task rather than using all parameters at once. This drastically reduces computing costs while maintaining high performance.
What is the significance of DeepSeek-R1’s reasoning capabilities?
DeepSeek-R1 excels in math, coding, and logical reasoning, outperforming many industry-leading models. It achieves this with a development cost of just $6 million, compared to the billions spent on models like GPT-4.
How does Janus Pro 7B achieve multimodal understanding?
Janus Pro 7B integrates text and image processing within a unified multimodal architecture, meaning it can analyze, understand, and generate both formats seamlessly. Unlike traditional multimodal models that use separate components for text and images, Janus Pro 7B processes both within a single streamlined framework.
Why is DeepSeek embracing open-source AI?
DeepSeek has released Janus Pro 7B under an MIT open-source license, allowing researchers and developers worldwide to build upon and refine the model. This approach fosters collaborative innovation and accelerates advancements in AI.
Does DeepSeek’s success challenge U.S. AI leadership?
DeepSeek’s rapid rise, despite U.S. export restrictions on high-end chips, signals that AI breakthroughs can come from software efficiency and algorithmic innovation, not just raw computational power. This has led to growing discussions on how the global AI race is evolving beyond traditional hardware advantages.
What the WolfPack Is Reading: (Sources used in the creation of this article, visuals, and podcast.)
How the buzz around Chinese AI model DeepSeek sparked a massive Nasdaq sell-off. CNBC. January 27, 2025
What Is China's DeepSeek and Why Is It Freaking Out the AI World? - BNN Bloomberg, accessed January 27, 2025,
DeepSeek v3 Blog. DeepSeek v3 Architecture.
Learn more at the DeepSeek blog and read the DeepSeek-V3 Technical Report.
What is Deepseek, Chinese AI model that rattled Chatgpt, Nvidia and freaked out AI world: Explained in 10 points - The Economic Times. January 27, 2025,
DeepSeek's New Open Source AI Model - Perplexity, accessed January 27, 2025, https://www.perplexity.ai/page/deepseek-s-new-open-source-ai-YwAwjp_IQKiAJ2l1qFhN9g
How China's new AI model DeepSeek is threatening U.S. dominance | Small Wars Journal by Arizona State University, January 27, 2025,
DeepSeek-R1 vs. OpenAI's o1: The Open-Source Disruptor Raising the Bar - GeekyAnts, January 27, 2025
The DeepSeek watershed moment: Why an open-source AI model from China is reshaping the global tech scene | CTech. January 27, 2025,
Explained: What Makes China's DeepSeek A Game-Changer In AI, NDTV. January 27, 2025,
What Is DeepSeek? New Chinese AI Startup Rivals OpenAI—And Claims It's Far Cheaper, Forbes. January 27, 2025,
China's DeepSeek AI poses formidable cyber, data privacy threats | Biometric Update. January 27, 2025
How DeepSeek's origins explain its AI model overtaking US rivals like ChatGPT | Technology News - The Indian Express, January 27, 2025,
What is DeepSeek? Chinese AI model outshining ChatGPT and shaking up the AI world. January 27, 2025
DeepSeek is highly biased, don't use it | by Mehul Gupta | Data Science in your pocket,January 27, 2025
DeepSeek-R1: Features, o1 Comparison, Distilled Models & More | DataCamp, accessed January 27, 2025, https://www.datacamp.com/blog/deepseek-r1
Deeply Seeking AI: DeepSeek R1 Shocks The AI World - BBN Times, January 27, 2025.
DeepSeek's New AI Assistant: A Game-Changer in the Tech World | AI News - OpenTools, January 27, 2025.
What is mixture of experts? IBM. 5 April 2024.
DeepSeek. en.wikipedia.org, accessed January 27, 2025
What is Chinese AI startup DeepSeek? Fox Business. January 27, 2025.
#AI #ArtificialIntelligence #DeepSeek #MachineLearning #OpenSourceAI #AIInnovation #MixtureOfExperts #TechDisruption #FutureOfAI #DeepLearning #AILeadership #AIModels #MultimodalAI #TechTrends








Share this post